Da questa pagina è possibile
- Ottenere informazioni sulle caratteristiche del sistema di interrrogazione e sui risultati ottenibili dalla consultazione del corpus MIDIA.
- Avere una descrizione del corpus MIDIA relativamente a: costituzione e organizzazione del corpus (scansione cronologica; tipologie di testi; dimensioni dei testi), fasi di realizzazione del corpus (preparazione dei testi del corpus; PoS tagging; revisione dei risultati automatici del PoS tagging; realizzazione del sistema di interrogazione).
- Consultare una estesa e aggiornata bibliografia sulla formazione delle parole in italiano.
- Consultare la lista degli studi su MIDIA o che hanno utilizzato MIDIA come corpus di riferimento di cui abbiamo notizia.
- Avere indicazioni su come citare MIDIA, e informazioni sul progetto PRIN 2009 "La storia della formazione delle parole in italiano" e sulle persone che hanno realizzato MIDIA
Tabella dei contenuti
Informazioni sulla consultazione del corpus MIDIA
In questa sezione sono fornite informazioni sull'utilizzo dell'interfaccia che consente di accedere online al corpus MIDIA. Il corpus può essere consultato per reperire sia singole forme sia lemmi. I risultati delle ricerche possono essere consultati online oppure scaricati.
Requisiti
Questa sezione offre una panoramica completa sui requisiti necessari per la corretta fruizione di MIDIA.
Browser
L'applicazione del corpus M.I.DIA. è stata realizzata e testata per supportare pienamente i seguenti browser:
- Internet Explorer 8 e superiori
- Firefox
- Chrome
- Opera
- Safari
Flash player (opzionale)
Flash player non è strettamente necessario per l'utilizzo di M.I.DIA.; tuttavia la funzionalità che permette di copiare una o più righe dei risultati della ricerca è disponibile solo se il player è installato nel sistema.
Tipi di ricerche
Questa sezione contiene le istruzioni e le informazioni sui possibili tipi di ricerca effettuabili. Il servizio di interrogazione del corpus MIDIA permette i seguenti tipi di ricerche: semplice; tramite espressione regolare; avanzata. Nel resto di questa pagina è possibile trovare informazioni relative al loro funzionamento sui filtri disponibili.
Ricerca semplice
La ricerca semplice consiste nell'immettere nel campo di ricerca una stringa che verrà cercata, in modo esattamente corrispondente alla forma inserita, all'interno del corpus. Il risultato di default è la forma cercata in contesto.
Ad esempio, se si cerca “porta” nel modo seguente:

si ottiene un risultato come il seguente, che comprende tutte le occorrenze sia del singolare del nome “porta”, sia delle omonime forme del verbo “portare” (III persona singolare del presente e II singolare dell’imperativo) presenti nel corpus:

Tramite un menù a tendina è possibile anche ricercare stringhe iniziali, finali o presenti all'interno di una forma del corpus.

Quindi, se si cerca “porta” come elemento iniziale di una parola

si ottiene un risultato come il seguente, che, rispetto al precedente, include tutte le forme del verbo “portare” inizianti con “porta” (portano, portare, portasse, ecc.) e i composti formati con “porta” (portabandiera, porta-finestra?) presenti nel corpus:

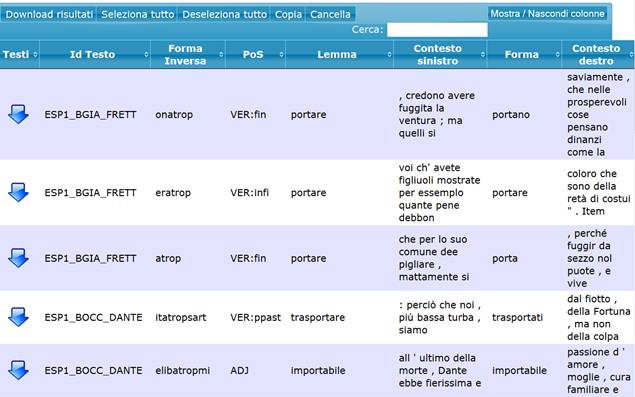
Se si cerca “porta” come elemento interno di una parola

si ottiene un risultato come il seguente, che contiene anche parole come trasportati, importabile, ecc., presenti nel corpus:
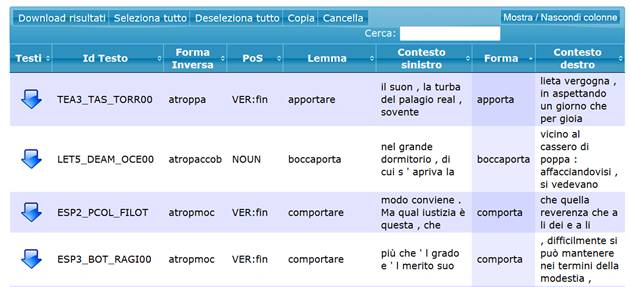
Se si cerca “porta” come elemento finale di una parola

si ottiene un risultato come il seguente, che comprende composti come boccaporta o apriporta e le forme della III persona singolare del presente indicativo e della II persona singolare dell’imperativo dei verbi portare, apportare, comportare, importare, riportare, ecc. presenti nel corpus:
Ricerca tramite Espressione regolare
La ricerca tramite espressione regolare si attiva cliccando sul quadratino a destra del campo di ricerca. Il risultato di default è la forma (o le forme) cercata in contesto.
L'attivazione dell'opzione "Espressione regolare" permette di svolgere ricerche su stringhe di caratteri utilizzando alcuni caratteri che svolgono funzioni di operatori. Nel sito web MIDIA si possono usare tutte le espressioni regolari che riguardano le caratteristiche di una singola forma o di più singole forme. Non sono accettate invece espressioni regolari che riguardano sequenze di forme; per cercare determinate sequenze di forme si deve utilizzare il sistema descritto alla sezione Posizione. Qui di seguito sono brevemente illustrati i valori dei caratteri che sono più utili nelle ricerche morfologiche e si danno alcuni esempi delle possibili combinazioni. Per maggiori informazioni sulle espressioni regolari e una guida esauriente sul loro uso, rimandiamo a http://en.wikipedia.org/wiki/Regular_expression.
- ?
- Il punto interrogativo indica zero o un'occorrenza del carattere che lo precede. Per esempio, colore? corrisponde sia a colore sia a color
- *
- L'asterisco indica zero o più occorrenze del carattere che lo precede. Per esempio, col*i corrisponde sia a coi sia a coli sia a colli
- +
- Il segno più indica una o più occorrenze del carattere che lo precede. Per esempio, col+i corrisponde sia a coli sia a colli, ma non a coi
- .
- il punto corrisponde a una occorrenza di un qualsiasi carattere. Per esempio co.i corrisponde a coci, coli, coni, cori, cosi, covi e così via.
- ( )
- Le parentesi tonde racchiudono gruppi di caratteri (per il loro uso, vedi l’esempio successivo relativo alla barra verticale).
- |
- la barra verticale corrisponde all'operatore booleano OR. Per esempio, puli(mento|tura) corrisponde sia a pulimento sia a pulitura
- [ ]
- le parentesi quadre identificano un singolo carattere fra quelli contenuti al loro interno. Per esempio, amav[aio] corrisponde sia a amava sia a amavi sia a amavo
- { }
- le parentesi graffe permettono di indicare il numero di occorrenze del carattere che le precede. Per esempio, lavora.{4} permette di trovare parole come lavorabile, lavoraccio, ma non lavorabilità, lavorante, lavorare. Un’interrogazione del tipo lavora.{3} permette di trovare parole come lavorante, lavorarle, lavoratie
Esempi d'uso e di combinazione degli operatori delle espressioni regolari
- dis.*: Cerca tutte le forme che iniziano con "dis".
- .*zione: Cerca tutte le forme/lemmi che terminano con "zione"
- scu.e: Cerca tutte le forme che iniziano con "scu" seguito da un carattere qualsiasi il quale precede "e" (ad esempio: scuce, scure, scuse, ecc.).
- let?ale: Cerca tutte le forme che iniziano con "le" seguito da zero o una occorrenza del carattere "t" il quale precede "ale" (ad esempio: leale e letale).
- fat+o: Cerca tutte le forme che iniziano con "fa" seguito da una o più occorrenze del carattere "t" il quale precede "o" (ad esempio: fatto e fato).
- interess(e|ante|are): Cerca tutte le forme/lemmi che iniziano con "interess" e terminano con "e" oppure "ante" oppure "are" (ad esempio: interesse, interessante, interessare).
- ri.+zzare: Cerca tutte le forme che cominciano con "ri", finiscono con "zzare" e nel mezzo ci sono un numero non definito di caratteri (ad esempio: ricozzare, ridrizzare, rimpiazzare).
- .+ori.: Cerca tutte le forme in cui la stringa "ori" sia preceduta da uno o più caratteri e seguita da un carattere (ad esempio: laboratorio e sparatoria).
- .+ori.{3}: Cerca tutte le forme in cui la stringa "ori" sia preceduta da uno o più caratteri e seguita da tre caratteri (esempi: adoriamo, favorisce, gloriosa, laborioso).
- .+ori(e|a|o): Cerca tutte le forme in cui la stringa "ori" sia preceduta da uno o più caratteri e seguita da "e" oppure "a" oppure "o" (ad esempio: gloriose, gloriosa, glorioso, ma non gloriosi).
- .+[ai]vano: Cerca tutte le forme che cominciano con un numero imprecisato di caratteri e terminano con "vano" preceduto da "a" oppure "i" (ad esempio: guardavano, guarivano, ma non volevano).
Ricerca avanzata
La ricerca semplice e quella con espressione regolare si possono raffinare tramite gli strumenti della ricerca avanzata. Questo tipo di ricerca usa i 4 filtri che possono essere visualizzati cliccando sul bottone "Opzioni avanzate", e il cui funzionamento è descritto nelle sezioni qui di seguito.
Dati sulla stringa
- Tipo stringa: Specifica se la stringa inserita nel campo di ricerca è da considerare una forma o un lemma. La scelta di default è "forma" (la scelta è indicata dal colore verde).

Cliccando su "lemma" si seleziona tale opzione, ed il bottone "lemma" diventa verde. - Parte del discorso: Specifica se il risultato deve mostrare i risultati a prescindere dalla classificazione in parti del discorso (PoS), oppure filtrare in base a una o più parti del discorso. Per selezionare una o più parti del discorso occorre cliccare sulla parte del discorso desiderata all'interno del menu a tendina.
Posizione
Questa opzione permette di restringere la ricerca individuando forme e/o lemmi che precedono o seguono quanto indicato nel campo ricerca.
- Forma Precedente: Specifica se ci deve essere un vincolo sulla forma che precede quella cercata.
- Parte del discorso Precedente: Specifica se ci deve essere un vincolo sulla parte del discorso della parola che precede quella cercata.
- Lemma Precedente: Specifica se ci deve essere un vincolo sul lemma cui appartiene la parola che precede quella cercata.
- Forma Successiva: Specifica se ci deve essere un vincolo sulla forma che segue quella cercata.
- Parte del discorso Successiva: Specifica se ci deve essere un vincolo sulla parte del discorso della parola che segue quella cercata.
- Lemma Successivo: Specifica se vi deve essere un vincolo sul lemma cui appartiene la parola che segue quella cercata.
Metadati
- Periodo: Filtra i risultati in base ai testi di uno o più periodi. Se non viene selezionato alcun periodo la ricerca avverrà su tutto il corpus. Per selezionare uno o più periodi occorre cliccare sul periodo desiderato all'interno del menu a tendina.
- Genere: Filtra i risultati in base ai testi di uno o più generi testuali. Se non viene selezionato alcun genere la ricerca avverrà su tutto il corpus. Per selezionare uno o più generi occorre cliccare sul genere desiderato all'interno del menu a tendina.
- Autore : Filtra i risultati in base ai testi di uno o più autori. Se non viene selezionato alcun autore la ricerca avverrà su tutto il corpus. Per selezionare uno o più autori occorre cliccare sull'autore desiderato all'interno del menu a tendina.
- Opera : Filtra i risultati in base ai testi di una o più opere. Se non viene selezionata alcuna opera la ricerca avverrà su tutto il corpus. Per selezionare una o più opere occorre cliccare sull'opera desiderata all'interno del menu a tendina.
Risultato
- Lista di esclusione: Permette di indicare eventuali forme da escludere dal risultato.
- Limite caratteri: Permette di indicare il numero minimo di caratteri che la stringa deve avere per non essere esclusa dal risultato.
- Ampiezza contesto: Permette di indicare il numero di forme da recuperare prima e dopo la stringa cercata. Il numero di default è 10 sia a sinistra sia a destra. Questo campo è attivo soltanto nel tipo di ricerca "In contesto".
Tipi di risultato
Per tutti i tipi di risultato è possibile visualizzare i dati online o scaricarli in formato CSV.
- In contesto: Vengono mostrate tutte le occorrenze della stringa richiesta assieme al contesto in cui essa appare (il valore di default è di 10 forme a sinistra e 10 a destra). I risultati della ricerca sono visualizzati in otto colonne: cliccando sulla prima colonna è possibile scaricare il testo del corpus in cui compare la forma cercata insieme alla scheda che contiene i metadati dell'opera da cui è tratto il testo; la seconda colonna contiene un codice identificativo dell'opera in cui compare la forma ricercata; la terza colonna contiene la forma cercata scritta in ordine inverso; la quarta colonna contiene l'indicazione della parte del discorso cui appartiene la forma; la quinta colonna contiene l'indicazione del lemma cui è ricondotta la forma; la sesta colonna contiene il contesto sinistro; la settima colonna contiene la forma; l'ottava colonna contiene il contesto destro. È possibile visualizzare online i risultati per un massimo di 5000 forme, mentre il download permette di ottenere tutti i risultati della ricerca.
- Tabella di distribuzione: Viene indicato in una tabella il numero di occorrenze della forma cercata distinte per generi e periodi.
- Lista frequenze: Viene indicato il numero di occorrenze della stringa cercata distinte per forma, parte del discorso e lemma.
- Evoluzione temporale: Visualizza una serie di grafici che mostrano l'uso della forma cercata in base ad autore, genere e periodo. Inoltre, viene mostrato un grafico cartesiano indicante il numero di occorrenze della forma cercata sull'asse temporale, distinte per genere testuale.
- Comparazione: Mette a confronto i risultati di più ricerche tramite un grafico che indica lungo l'asse temporale il numero di occorrenze delle forme selezionate.
Lavorare con i risultati
Questa sezione spiega cosa è possibile fare con i risultati ottenuti con la ricerca "In contesto".
Scaricare i risultati
L'opzione più utile è probabilmente quella che permette di scaricare i dati ottenuti dal risultato "In contesto". Cliccando sul bottone "Download risultati" si ottiene un file in formato CSV. Come si è già detto, tramite "Download risultati" si ottengono tutti i risultati della ricerca, mentre la visualizzazione online permette di ottenere e di intervenire online su di un numero massimo di 5000 risultati. Cliccando sulla freccia della colonna "Testi" è possibile anche scaricare il testo dell'opera in cui è presente una determinata occorrenza e la relativa scheda di metadati.
Riordinare le colonne
Per riordinare le colonne basta cliccare sull'intestazione di quella che si vuole spostare e posizionarla dove è più gradito.
Riordinare i risultati
I risultati possono essere riordinati in ordine sia crescente sia decrescente per ognuno dei valori presenti nella tabella. Per effettuare l'ordinamento è sufficiente cliccare sull'intestazione della colonna secondo la quale si vuole ordinare.
Selezionare una o più righe
Per selezionare una riga è sufficiente cliccare su di essa. Per annullare le selezioni effettuate basta cliccare il pulsante "Deseleziona tutto".
Copiare una o più righe
Per copiare una o più righe si deve dapprima selezionare le righe desiderate e poi cliccare sul bottone "Copia".
Cancellare una o più righe
Per cancellare una o più righe si deve dapprima selezionare le righe desiderate e poi cliccare sul bottone "Cancella".
Filtrare i risultati
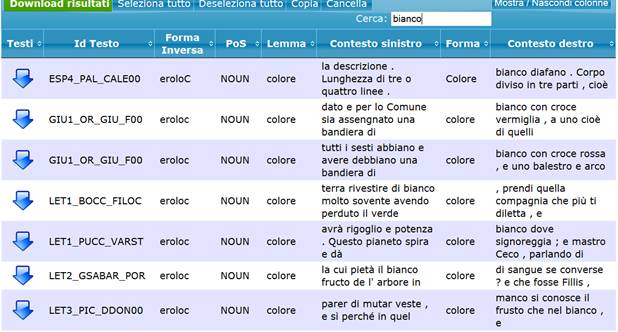
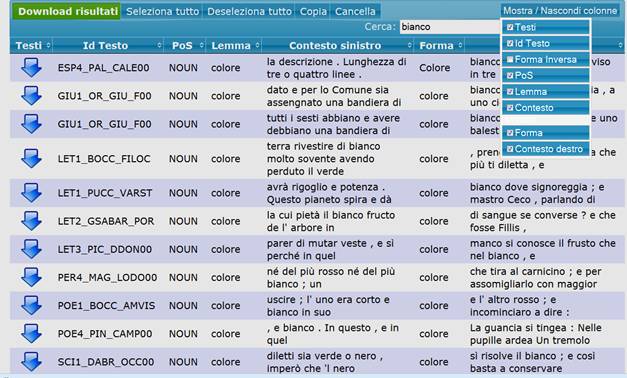
I risultati ottenuti online possono essere ulteriormente filtrati utilizzando l'apposito box indicato con la scritta "Cerca", che permette di individuare stringhe di caratteri all'interno dei risultati della ricerca in contesto. Viene qui sotto riprodotta la ricerca della forma "colore" tra i cui risultati vengono individuati quelli in cui appare la forma "bianco".
Nascondere una o più colonne
Durante la consultazione della ricerca può essere utile ignorare alcune delle colonne mostrate. Per utilizzare questo filtro, basta cliccare sul pulsante “Mostra / Nascondi colonne”, deselezionando quelle che non sono interessanti ai fini della ricerca. Nell'esempio seguente, è stata nascosta la colonna "Forma inversa". Per riattivare le colonne nascoste è sufficiente cliccare nell'apposito riquadro.
Esempi d'uso
Questa sezione illustra alcuni casi d'uso della nostra applicazione.
Esempio 1 - Mostrare una forma seguita da un'altra in contesto
Questo esempio descrive i passi da compiere per ottenere una tabella che mostri la rappresentazione nel corpus di una data forma seguita da un'altra forma a scelta, che rispetti dei vincoli temporali e di genere, in un contesto di 40 forme, ovvero 20 a sinistra e 20 a destra. Si tenga presente che i segni di interpunzione presenti nel testo vengono contati come forme del contesto.
In dettaglio, i vincoli della ricerca saranno i seguenti:
- La parola cercata è "andare"
- La parola deve essere interpretata come forma
- La forma cercata deve essere seguita dalla forma "via"
- I periodi di interesse sono: "1376-1525", "1526-1691" e "1841-1945"
- I generi di interesse sono: "Poesia" e "Prosa Letteraria"
- L'elaborazione deve mostrare la forma in contesto
Passo 1
Il primo passo consiste nell'inserire nel campo "Cerca" la parola andare come mostrato dalla figura A.1.

Passo 2
Cliccare sul bottone "Opzioni avanzate". Nella prima sezione chiamata "Dati sulla stringa", cliccare su "Tipo stringa" e selezionare la voce "Forma" (valore predefinito). A conferma dell'avvenuta selezione, il colore dovrebbe essere verde come mostrato dalla figura A.2.
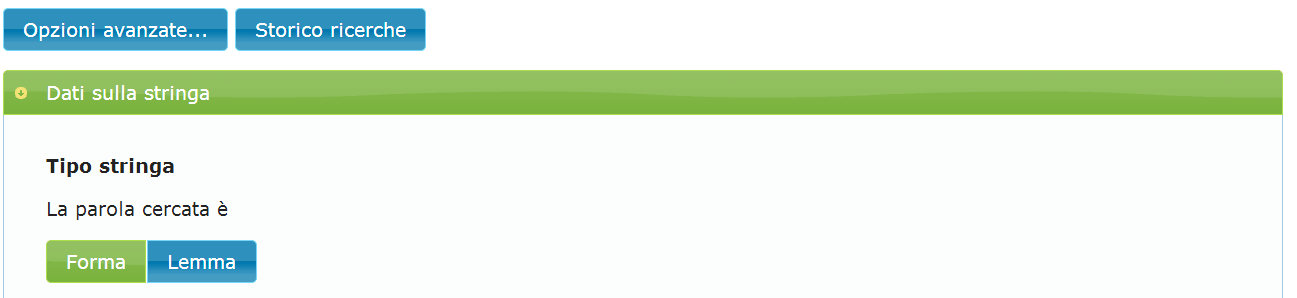
Passo 3
Guardare verso il basso fino a trovare la sezione "Posizione" e selezionarla affinché vengano visualizzate le opzioni contenute. A questo punto, inserire nel campo "Forma" della sotto-sezione "Successiva" la parola via come mostrato dalla figura A.3.

Passo 4
Cliccare sulla sezione "Metadati" per visualizzare tutte le opzioni di ricerca contenute. Selezionare i periodi e i generi di interesse nelle rispettive caselle così che risultino evidenziati. Alla fine della selezione si dovrebbe ottenere il risultato mostrato da figura A.4.
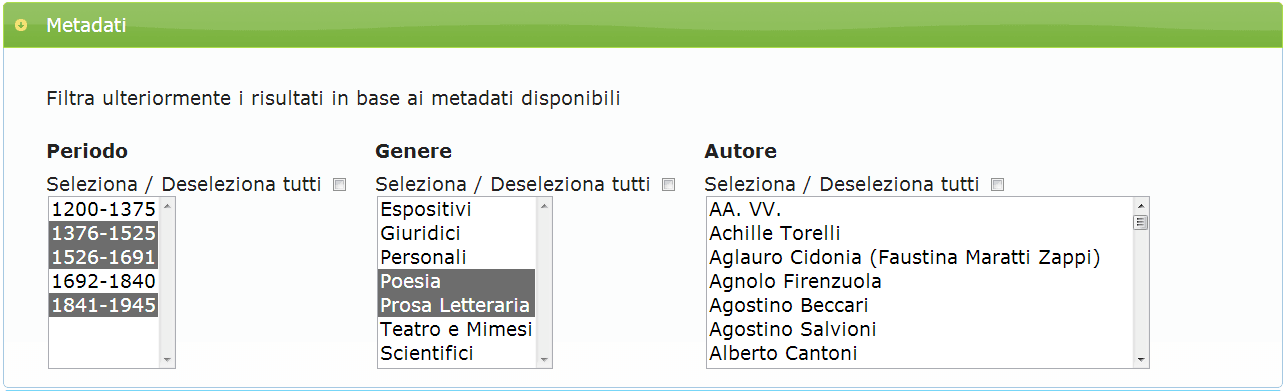
Passo 5
Alla sezione “Risultato”, cliccare sul bottone "In contesto" (valore predefinito). A conferma dell'avvenuta selezione, il colore dovrebbe essere verde. In basso alla voce "Numero di parole da recuperare come contesto", cambiare il valore in 20 (il valore predefinito è 10). Alla fine delle selezioni, i criteri di ricerca riguardanti il tipo di risultato appariranno in una schermata come quella riportata in figura A.5.
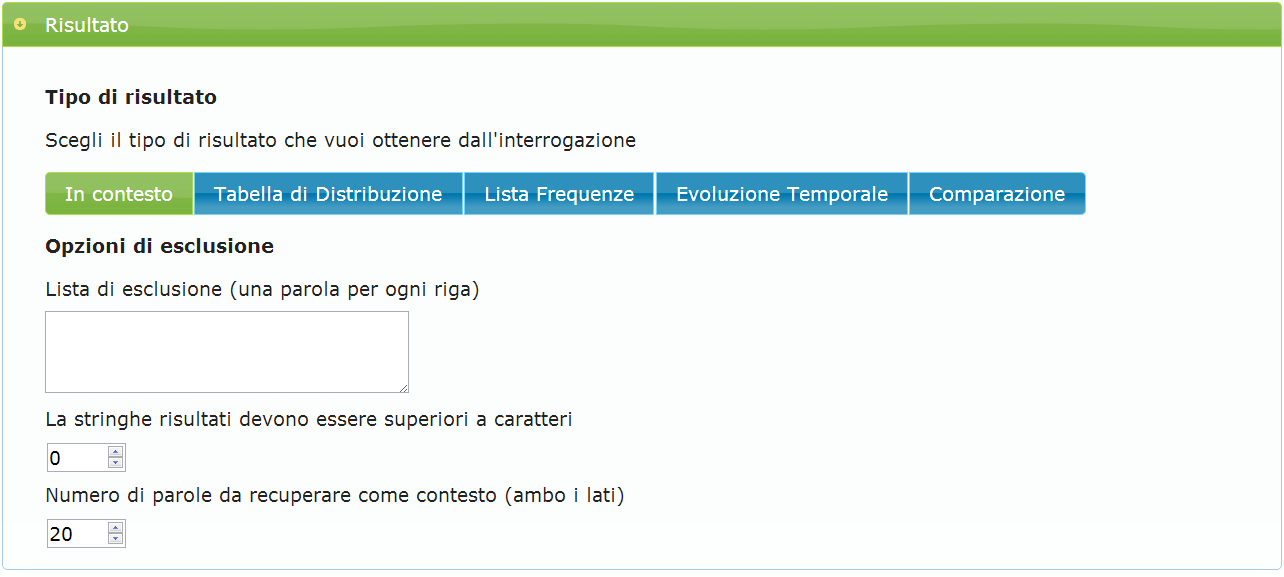
Passo 6
Cliccare il tasto "Cerca" per dare l’avvio all'elaborazione dei dati.
Mostrare la lista di frequenza di un lemma seguito e preceduto da una forma avente una PoS di interesse
Questo esempio descrive i passi da seguire per ottenere una tabella che mostri un lemma seguito e preceduto da una forma avente una specifica PoS.
In dettaglio, i vincoli della ricerca saranno i seguenti:
- La parola cercata è "essere"
- La parola deve essere interpretata come lemma
- Il lemma cercato deve essere preceduto da un Articolo
- Il lemma cercato deve essere seguito da un Verbo
- L'elaborazione deve mostrare la lista di frequenza
Passo 1
Il primo passo consiste nell'inserire nel campo "Cerca" la parola essere come mostrato dalla figura B.1.

Passo 2
Cliccare sul bottone "Opzioni avanzate". Nella prima sezione chiamata "Dati sulla stringa", cliccare su "Tipo stringa" e selezionare la voce "Lemma". A conferma dell'avvenuta selezione, il colore dovrebbe essere verde come mostrato dalla figura B.2.

Passo 3
Andare alla sezione "Posizione" alla sottosezione "Precedente" e cliccare la voce "Articolo" del menu "Parte del discorso". Poi, andare alla sottosezione "Successiva" e cliccare la voce "Verbo" del menu "Parte del discorso", come mostrato dalla figura B.3.
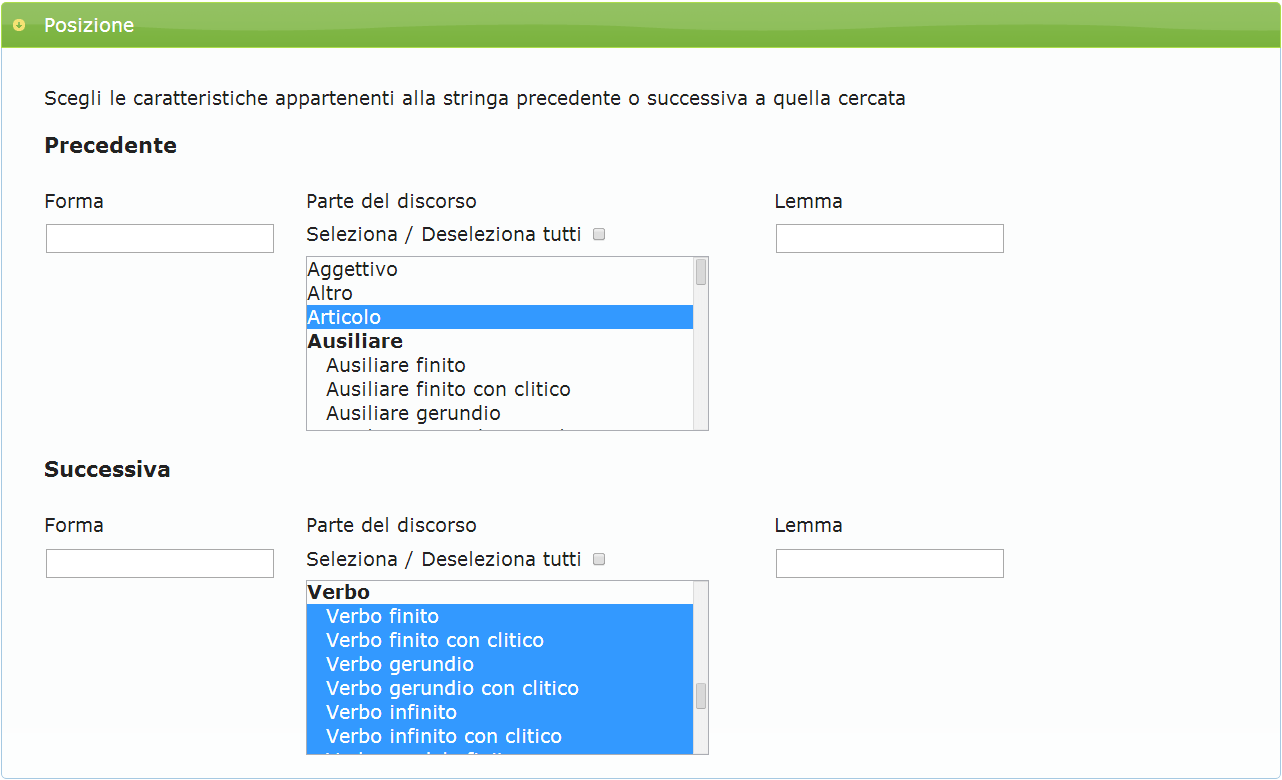
Passo 4
Alla sezione “Risultato”, cliccare sul bottone "Lista Frequenze". A conferma dell'avvenuta selezione, il colore dovrebbe essere verde come riportato in figura B.4.

Passo 5
Cliccare il tasto "Cerca" per dare avvio all'elaborazione dei dati.
Descrizione del corpus MIDIA
MIDIA (acronimo di "Morfologia dell'Italiano in DIAcronia") permette l'interrogazione di un corpus testuale finalizzato allo studio della formazione delle parole in italiano dal punto di vista diacronico. Il corpus di testi italiani copre un periodo di 7 secoli (dal Duecento al 1947) e comprende 7 tipologie testuali. La lemmatizzazione e la categorizzazione in parti del discorso sono state ottenute grazie al programma Tree-Tagger modificato e arricchito in modo da renderlo adatto all'analisi della varietà della lingua italiana nel lungo periodo temporale preso in esame.
Costituzione e organizzazione del corpus
Scansione cronologica
In un'ottica di storia linguistica interna, si è scelta una suddivisione cronologica scandita da importanti fatti di storia linguistica, letteraria e culturale che possono essere considerati come punti di svolta nella storia della lingua italiana. Sono così stati individuati cinque periodi: I. Dall'inizio del Duecento al 1375; II. Dal 1376 al 1532; III. Dal 1533 al 1691; IV. Dal 1692 al 1840; V. Dal 1841 al 1947. Criteri della suddivisione temporale:
- Dall'inizio del Duecento al 1375: dallo sviluppo della letteratura (e in genere della scrittura in volgare) in area toscana fino all'anno della morte di Boccaccio e dell'inizio dell'attività cancelleresca da parte di Coluccio Salutati; la data finale è la stessa che delimita il corpus testuale dell'OVI - TLIO.
- Dal 1375 al 1532: il periodo abbraccia l'esperienza dell'Umanesimo e del Rinascimento, tra lo sviluppo del fiorentino "argenteo" e la scelta in direzione classicista del fiorentino "aureo" teorizzata nelle Prose della volgar lingua di Pietro Bembo (1525). Il periodo ha come data finale quella della delle terza edizione dell'Orlando Furioso, attuazione in poesia delle teorie bembiane.
- Dal 1533 al 1691: periodo del tardo Rinascimento / Manierismo e del Barocco. La data di chiusura coincide con la terza edizione del Vocabolario degli Accademici della Crusca (1691), all'indomani della fondazione dell'Arcadia (1690).
- Dal 1692 al 1840: comprende l'età dell'Arcadia, dell'Illuminismo e del Romanticismo: è questa l'epoca in cui alcuni studiosi (Durante, Tesi) hanno collocato la nascita dell'italiano moderno. Il periodo termina con l'edizione definitiva dei Promessi sposi, basata, come è noto, sul fiorentino dell'uso vivo, e per tanti aspetti modello linguistico dell'italiano postunitario.
- Dal 1841 al 1947: è il periodo del Risorgimento, dell'Italia unita e delle due guerre mondiali, fino all'avvento della Repubblica e alla promulgazione della Costituzione. Sull’importanza linguistica dell’unificazione hanno giustamente insistito vari studiosi, primo fra tutti Tullio De Mauro (1963), che più di recente (2014) ha valorizzato anche, sul piano linguistico, il periodo della repubblica. L'approdo quasi alla metà del Novecento – prima, dunque, di quest’ultima fase – fa sì fa sì che i testi selezionati, pur se non troppo lontani del tempo, possano fornire elementi differenti in diacronia rispetto all'italiano contemporaneo oggetto degli studi più recenti sulla formazione delle parole.
La selezione dei testi all'interno dei vari periodi è stata effettuata in modo da distribuirli (quando possibile) lungo l'intero arco cronologico di ogni periodo. Al criterio storico si è affiancato quello geografico. Il corpus riguarda la lingua italiana in prospettiva diacronica, e non comprende gli altri sistemi linguistici del dominio italo-romanzo. Pertanto, nel periodo I, sono stati inclusi esclusivamente testi toscani o toscanizzati, come le rime della scuola siciliana; ciò è avvenuto, in linea di massima, anche nel periodo II, in cui però in alcuni generi (non la Poesia e la Prosa letteraria) si è dovuto inserire (sulla base del materiale reperito) qualche testo in “volgare illustre” di diversa provenienza. Invece, nei periodi III-V sono stati raccolti testi in italiano di varia provenienza geografica, anche per permettere di valutare la possibile matrice locale di alcuni procedimenti di formazione delle parole o per registrare possibili differenze spiegabili con la diatopia.
Tipologie di testi
I testi sono stati selezionati in base all’appartenenza a sette tipologie testuali: Testi espositivi (es., trattati non scientifici, stampa, pubblicistica); Testi giuridico-amministrativi (es., statuti, leggi); Testi personali (lettere, diari, ecc.); Poesia; Prosa letteraria; Testi scientifici; Teatro, oratoria, mimesi dialogica.
Oltre alla tradizionale distinzione, all'interno dei testi letterari, tra prosa e poesia, si è dato autonomo spazio alla letteratura teatrale, accostata a testi scritti in vista di una fruizione orale o derivati dal parlato (es., prediche, discorsi, verbali di processi) e ad altre simulazioni di dialogo (es., manuali di conversazione), al fine di cogliere fenomeni rappresentativi della modalità parlata. Sono stati inseriti in questa sezione anche opere in versi (tragedie, melodrammi), che presentano tratti di "oralità spettacolare" distinti, ma non sempre inconciliabili, da quelli propri delle commedie in prosa.
Le altre quattro sezioni rappresentano le maggiori novità del corpus. Una è costituita da testi personali (es., lettere, autobiografie, diari, memorie, libri di conti), non destinati alla pubblicazione e che, dato il loro carattere privato, possono aprire finestre su aspetti della lingua d'uso, che molte persone colte utilizzavano nei secoli passati accanto al dialetto, specialmente in ambito familiare. La sezione dei testi espositivi comprende trattati, saggi, descrizioni, biografie, ecc., opere non rientranti nella categoria della "prosa d'arte" e disponibili ad accogliere tecnicismi e voci di matrice locale
La sezione dei testi scientifici comprende soprattutto opere che hanno per oggetto la matematica, la fisica, la biologia, la chimica, la medicina (le cosiddette "scienze dure"); non mancano però, nei periodi più recenti, testi di statistica, psicologia, ecc., mentre la fase "prescientifica" accoglie opere di alchimia, bestiari, volgarizzamenti di trattati scientifici classici, ecc.
Tra i testi giuridici sono stati inseriti leggi, regolamenti, statuti, atti amministrativi. Per avere l'elenco dei testi del corpus MIDIA cliccare qui.
Dimensione dei testi
Di ogni tipo testuale si è deciso di selezionare 25 testi per ciascun periodo. Di ogni testo è stata selezionata una sezione di circa 8000 occorrenze (per un totale complessivo di circa 7,5 milioni di occorrenze). Il corpus, pur non amplissimo, risulta così molto equilibrato al suo interno. Solo nel primo periodo la quantità dei testi teatrali e personali risulta inferiore a quella degli altri a causa della scarsità di opere reperibili. Nel caso in cui qualche periodo e qualche sezione testuale è risultata particolarmente "sguarnita", per raggiungere la quantità prefissata di parole si è provveduto a "raddoppiare" la quantità di testi scritti da autori particolarmente importanti (es. Boccaccio, Galilei, ecc.).
| Periodi | Espositivi | Giuridici | Personali | Poesia | Prosa | Scientifici | Teatro | Totale periodo |
|---|---|---|---|---|---|---|---|---|
| I | 112385 | 438295 | 8447 | 207484 | 223891 | 237634 | 55514 | 1274850 |
| II | 279101 | 206130 | 251838 | 264792 | 218144 | 231749 | 194674 | 1646428 |
| III | 239517 | 261990 | 216887 | 242498 | 220798 | 268389 | 256270 | 1706349 |
| IV | 231988 | 199499 | 223654 | 204115 | 211777 | 215269 | 192704 | 1470706 |
| V | 263565 | 250541 | 268492 | 242858 | 224358 | 215559 | 217685 | 1683058 |
| Totale corpus | ||||||||
| Tot. Genere | 1126556 | 1356455 | 969318 | 1161747 | 1090168 | 1160300 | 916847 | 7790191 |
Molti testi sono stati attinti da corpora già disponibili in formato elettronico. Alcuni sono stati acquisiti in formato elettronico grazie al diretto contatto con editori o gruppi di ricerca. Per un numero non trascurabile di testi si è proceduto alla scansione con programma OCR e alla conversione in formato txt. Tutti i testi sono stati sottoposti a revisione manuale.
Fasi di realizzazione del corpus MIDIA
Nella realizzazione del corpus MIDIA, possono essere individuate 4 fasi:
- la preparazione dei testi del corpus già selezionati e acquisiti;
- il PoS tagging;
- la revisione manuale dei risultati automatici del PoS tagging;
- la realizzazione del sistema di interrogazione.
Preparazione dei testi del corpus
Un lavoro preliminare all'analisi informatica è consistito nella revisione dei testi acquisiti. Si è trattato di un lavoro quasi in gran parte manuale mirante soprattutto a risolvere problemi di compatibilità dei caratteri e di eliminazione di porzioni di testo che potevano ridurre la rappresentatività del corpus.
Tree-Tagger, il programma impiegato per la classificazione in parti del discorso, su Windows lavora meglio utilizzando la codifica ISO-8859-1 piuttosto che sulla più estesa codifica UTF-8. Per questa ragione, per alcuni testi già in formato digitale è stata necessaria una revisione che ha condotto alla sostituzione di alcuni caratteri comuni assenti dalla codifica richiesta (es. ‘«’ e ‘»’ sono stati sostituiti con ‘"’).
Per facilitare il riconoscimento delle forme da parte del programma è stato necessario isolare le parole da alcuni diacritici e segni di interpunzione (ad esempio inserendo un spazio dopo l'apostrofo usato per indicare l'elisione delle vocali degli articoli lo, la e una).
Si è deciso di trattare alcune porzioni dei testi originali in modo che non fossero analizzate dal programma di PoS tagging. Tale intervento ha riguardato principalmente gli indicatori ripetuti di scansione del testo. In questa categoria rientrano le indicazioni capitolo, parte, libro, sezione, oppure presenti nei testi giuridici, e – dato da sottolineare – le didascalie dei testi teatrali, in cui sono indicati i nomi dei personaggi dialoganti, la progressione delle scene, l'ingresso e l'uscita dei personaggi, informazioni di tipo descrittivo o narrativo sull'ambiente e il tempo in cui si svolge l'azione. In testi giuridici e testi teatrali tali elementi possono arrivare al 10% del totale del testo.
PoS tagging
Il programma che è stato usato per associare a ciascuna forma una parte del discorso e un lemma è Tree-Tagger. Tra i tre files di parametri della lingua italiana disponibili per TreeTagger (tutti realizzati per l'analisi dell'italiano contemporaneo), il più adatto alle nostre esigenze si è rivelato quello realizzato da Marco Baroni a partire dal corpus Morph-it!. Ma anche tale file di parametri non si è dimostrato completamente adeguato per l'analisi di stadi precedenti della lingua italiana.
Grazie anche alla disponibilità di Marco Baroni, abbiamo potuto generare e utilizzare per MIDIA un nuovo file di parametri che permette risultati migliori nell'analisi di testi appartenenti a tutto l'arco della storia della lingua italiana. Tale risultato è stato raggiunto soprattutto tramite l'aggiunta al formario del corpus dell'italiano contemporaneo di circa 200.000 forme risalenti perlopiù al periodo che va dal XIV al XVI secolo. Oltre all'aggiunta di forme, la revisione del formario ha determinato una ridefinizione dei criteri di lemmatizzazione (che tiene conto della ricca allotropia caratteristica della storia della lingua italiana) e una parziale modifica (rispetto a quella del file di parametri di partenza) della lista delle parti del discorso utilizzate in MIDIA. Per avere la tabella con l'elenco delle parti del discorso utilizzate in MIDIA e relative abbreviazioni cliccare qui.
Il formario usato per la lemmatizzazione e l’attribuzione della parte del discorso alle forme presenti nel corpus MIDIA conta attualmente circa 550.000 forme.
Revisione dei risultati automatici del PoS tagging
La revisione dei risultati automatici del PoS tagging è avvenuta in due diversi momenti. Nelle fasi iniziali del lavoro è servita a definire gli interventi necessari per ampliare il formario e ridefinire la lista delle parti del discorso utilizzate in MIDIA. In fase di post-elaborazione è servita per correggere manualmente alcuni errori di assegnazione di parte del discorso o di lemmatizzazione da parte della versione da noi implementata di Tree-Tagger. La revisione manuale è consistita nel filtraggio delle forme per le PoS attribuite dal programma e in una correzione mirata. Per ottimizzare i tempi e le risorse umane, si è operato su forme contenenti stringhe finali corrispondenti ai più comuni suffissi derivazionali e sulle forme di più alta frequenza.
Realizzazione del sistema di interrogazione
L'interfaccia che consente di accedere online al corpus MIDIA costituisce uno strumento semplice e allo stesso tempo potente per consultare il corpus. Essa è concepita per utenti con necessità diverse in termini di usabilità e di efficacia delle ricerche: permette infatti un immediato accesso alle ricerche semplici e diversi filtri per ricerche complesse. I risultati delle ricerche possono essere scaricati o consultati online.
Il servizio web del corpus MIDIA è stato realizzato per essere eseguito indifferentemente su piattaforma WAMP (Windows Apache MySql PHP) o LAMP (Linux Apache MySql PHP). I dati del corpus MIDIA sono salvati in un database RDBMS MySql progettato ed implementato rivolgendo particolare attenzione alle prestazioni, data la grande quantità di dati. Il codice sorgente è stato scritto in linguaggio PHP. Tutte le funzionalità del servizio sono state sviluppate sotto forma di un'unica libreria costituita da circa 20.000 linee di codice, realizzata da Aurelio De Rosa e rilasciata sotto licenza CC BY-NC 4.0 (Creative Commons Attribuzione - Non commerciale 4.0 Internazionale). Da tale conteggio sono escluse le funzionalità di software di terze parti integrate nel progetto. Tali dipendenze software sono state gestite tramite la libreria Composer.
Bibliografia sulla formazione delle parole in italiano
In questa sezione è possibile trovare un'ampia bibliografia sulla formazione delle parole in italiano curata da Maria Grossmann. La bibliografia segue l'ordine alfabetico di autore (di ogni autore gli studi sono disposti in ordine cronologico) ed è completata dall'elenco delle sigle usate per la citazione delle riviste. Sono compresi nella bibliografia:
- le monografie e gli articoli specificamente dedicati alla formazione delle parole in italiano, sia in sincronia sia in diacronia;
- gli studi che comprendono significativi riferimenti alla formazione delle parole in italiano, pur trattando della morfologia derivazionale dal punto di vista teorico o in una prospettiva romanza;
- i lavori dedicati alla formazione delle parole nel latino, importanti anche per lo studio dell'italiano;
- gli studi linguistici che, pur non essendo specificamente dedicati alla formazione delle parole, perché vertenti su singoli autori, testi, epoche e correnti della storia linguistica italiana, o su questioni relative al lessico, dedicano un certo spazio alla formazione delle parole.
Invitiamo quanti la consulteranno a segnalare aggiunte, aggiornamenti, correzioni, ecc. inviando una email a Maria Grossmann (maria.grossmann@cc.univaq.it).
Lavori su e con MIDIA --SEZIONE IN AGGIORNAMENTO--

Citazione di MIDIA e contatti
Questa pagina fornisce indicazioni su come citare e come contattare MIDIA, informazioni sul progetto PRIN 2009 "La storia della formazione delle parole in italiano" e sulle persone che hanno realizzato MIDIA
Se pubblicate lavori basati su MIDIA, vi invitiamo a citare il link www.corpusmidia.unito.it e rimandare al volume D’Achille P., Grossmann M. (eds.), Per la storia della formazione delle parole in italiano: un nuovo corpus in rete (MIDIA) e nuove prospettive di studio, Firenze, Franco Cesati, 2017.
Contiamo sulle vostre segnalazioni per migliorare il sito e correggere inevitabili errori nella classificazione del corpus. Per segnalazioni, potete spedirci una mail all'indirizzo infocorpusmidia@gmail.com
MIDIA è stato realizzato grazie al finanziamento del progetto Prin 2009 "La storia della formazione delle parole in italiano" coordinato da Paolo D'Achille (Università Roma Tre), a cui hanno partecipato altre tre unità di ricerca: Università di Napoli Federico II (responsabili prima Livio Gaeta e poi Michela Cennamo), Università di Salerno (responsabile Claudio Iacobini), Università di Torino (responsabile Davide Ricca). Hanno fatto inoltre parte del progetto: nell'unità di Roma Tre Ilde Consales, Claudio Giovanardi, Antonella Stefinlongo, Andrea Viviani, e Antonietta Bisetto (Università di Bologna), Maria Grossmann (Università dell'Aquila), Franz Rainer (Wirtschaftsuniversität Wien), e Riccardo Cimaglia (assegnista); nell'unità di Salerno Grazia Basile, Renata Savy, Miriam Voghera, e Anna M. Thornton (Università dell'Aquila) e Giovanna Schirato (assegnista); nell'unità di Torino Mario Squartini, Livio Gaeta (dopo il suo trasferimento) e Marco Angster (assegnista).
I lavori di realizzazione del sito web sono stati coordinati da Claudio Iacobini con la collaborazione di Aurelio De Rosa, Giovanna Schirato, Claudia Fabrizio, e l'aiuto di Eleonora Ferolla, Chiara Iannuzzi, Antonella Scarpa.
I programmi informatici sono stati realizzati da Aurelio De Rosa.
La selezione dei testi è stata curata da Paolo D'Achille e Riccardo Cimaglia, con la collaborazione di Ilde Consales, Claudio Giovanardi, Antonella Stefinlongo, Andrea Viviani, Domenico Proietti e Giovanna Schirato.
La preparazione dei testi è opera di Marco Angster, Riccardo Cimaglia, Aurelio De Rosa, Claudia Fabrizio, Giovanna Schirato, Andrea Viviani.
Hanno lavorato alla revisione della lemmatizzazione: Alfonsina Buoniconto, Luisa Corona, Aurelio De Rosa, Claudia Fabrizio, Claudio Iacobini, Chiara Iannuzzi, Diana Passino, Davide Ricca, Antonella Scarpa, Giovanna Schirato, Anna M. Thornton.
La bibliografia sulla formazione delle parole in italiano è stata curata da Maria Grossmann.
Il corpus MIDIA è distribuito con
licenza CC BY-NC
4.0 (Creative Commons Attribuzione - Non commerciale 4.0 Internazionale).
![]()